Doing Bayesian Data Analysis
2013.04.14 Leave a comment
Assuming I can keep at it, I’ll be making my way through Kruschke’s Doing Bayesian Data Analysis. Here’s a few concepts he goes through in Chapter 4.
The Bayes factor
This is a ratio which allows you to compare which out of two models best fits the data. By introducing a binary parameter which determines the choice of model, Bayes’ rule

gives us the Bayes factor
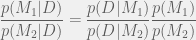
or also
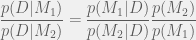
Note that if we have no prior preference between the two models, these ratios are equal.
The Bayes’ factor is useful because on their own 
Data order invariance
I don’t get this part – it’s always true that 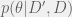
The problem with Bayesian mathematics
Computing the posterior given some new data usually means performing an integral, which, even using approximations, can be computationally intensive (especially since the posterior will be fed into an optimizer). Numerical integration on the other hand would impose a limit on the dimensionality of the model. Thus we winning method is Markov Chain Monte Carlo (MCMC).

Recent Comments