Introduction
You’re allergic to learning curves and want to get your code generated now! Here’s an easily customized 100-line Python module just a notch above f.writeline.
Using the code
Let’s start with a really simple example (no pointing out that main returns int please! It’s an example.)
from CodeGen import *
cpp = CppFile("test.cpp")
cpp("#include <iostream>")
with cpp.block("void main()"):
for i in range(5):
cpp('std::cout << + str(i) + '" << std::endl;')
cpp.close()
The output:
#include <iostream>
void main()
{
std::cout << "0" << std::endl;
std::cout << "1" << std::endl;
std::cout << "2" << std::endl;
std::cout << "3" << std::endl;
std::cout << "4" << std::endl;
}
Leveraging Python’s with keyword we can encapsulate statements in {} blocks which get closed out automatically, with the correct indentation so that the output remains human-readable.
Substitutions
When generating more sophisticated code, you’ll quickly realize your Python script becomes progressively less readable with ugly string concatenations all over the place. That’s where the subs method come in:
from CodeGen import *
cpp = CppFile("test.cpp")
cpp("#include <iostream>")
with cpp.block("void main()"):
for i in range(5):
with cpp.subs(i=str(i), xi="x"+str(i+1)):
cpp('int $xi$ = $i$;')
cpp.close()
which produces:
#include <iostream>
void main()
{
int x1 = 0;
int x2 = 1;
int x3 = 2;
int x4 = 3;
int x5 = 4;
}
The substitutions are valid within the Python with block, which can be nested.
That’s pretty much it
To finish off here’s a more complicated example to generate the following code:
class ClassX
{
protected:
A a;
B b;
C c;
public:
ClassX(A a, B b, C c)
{
this->a = a;
this->b = b;
this->c = c;
}
A getA()
{
return this->a;
}
B getB()
{
return this->b;
}
C getC()
{
return this->c;
}
};
class ClassY
{
protected:
P p;
Q q;
public:
ClassY(P p, Q q)
{
this->p = p;
this->q = q;
}
P getP()
{
return this->p;
}
Q getQ()
{
return this->q;
}
};
Take a look at CodeGen.py to see how the label function is implemented for a hint on how to extend the code with language-specific features.
from CodeGen import *
cpp = CppFile("test.cpp")
CLASS_NAMES = ["ClassX", "ClassY"]
VAR_NAMES = { "ClassX": ["A", "B", "C"],
"ClassY": ["P","Q"] }
for className in CLASS_NAMES:
with cpp.subs(ClassName=className):
with cpp.block("class $ClassName$", ";"):
cpp.label("protected")
for varName in VAR_NAMES[className]:
with cpp.subs(A=varName, a=varName.lower()):
cpp("$A$ $a$;")
cpp.label("public")
with cpp.subs(**{"A a": ", ".join([x + " " + x.lower() for x in VAR_NAMES[className]])}):
with cpp.block("$ClassName$($A a$)"):
for varName in VAR_NAMES[className]:
with cpp.subs(a=varName.lower()):
cpp("this->$a$ = $a$;")
for varName in VAR_NAMES[className]:
with cpp.subs(A=varName, a=varName.lower(), getA="get"+varName):
with cpp.block("$A$ $getA$()"):
cpp("return this->$a$;")
cpp.close()

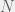

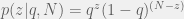


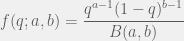


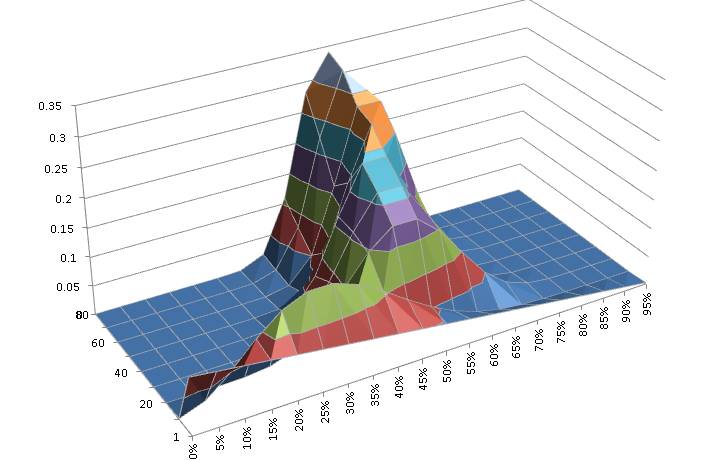

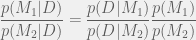
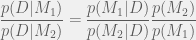
 scale on the basis of the model – the more complex the model, the lower the absolute value – but this is actually a good thing because by considering the ratio we automatically trade off complexity (when there’s little data) against descriptive value (when the simpler model doesn’t fit the data).
scale on the basis of the model – the more complex the model, the lower the absolute value – but this is actually a good thing because by considering the ratio we automatically trade off complexity (when there’s little data) against descriptive value (when the simpler model doesn’t fit the data).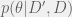 is invariant of the order in which Bayes’ rule is applied, by definition. The factorized rule cited at the end is just the result of applying the definition of data independence given the parameters.
is invariant of the order in which Bayes’ rule is applied, by definition. The factorized rule cited at the end is just the result of applying the definition of data independence given the parameters.
Recent Comments