The simplest possible Bayesian model
2013.04.16 Leave a comment
MathJax.Hub.Config({
extensions: [“tex2jax.js”],
jax: [“input/TeX”, “output/HTML-CSS”],
tex2jax: {
inlineMath: [ [‘$’,’$’], [“\\(“,”\\)”] ],
displayMath: [ [‘$$’,’$$’], [“\\[“,”\\]”] ],
processEscapes: true
},
“HTML-CSS”: { availableFonts: [“TeX”] }
});
In chapter 5, Kruschke goes through the process of using Bayes’ rule for updating belief in the ‘lopsidedness’ of a coin. Instead of using R I decided to try implementing the model in Excel.
The Model
Coin tosses are IID with a 
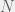

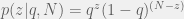
Using Bayes’ rule we get

Note that if 
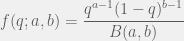
where the denominator is a normalizing constant then 
Excel implementation
This is very straight-forward using the BETADIST function, which is cumulative, so we divide the unit interval into equally spaced subintervals, calculate the probability of 
Here’s the result.
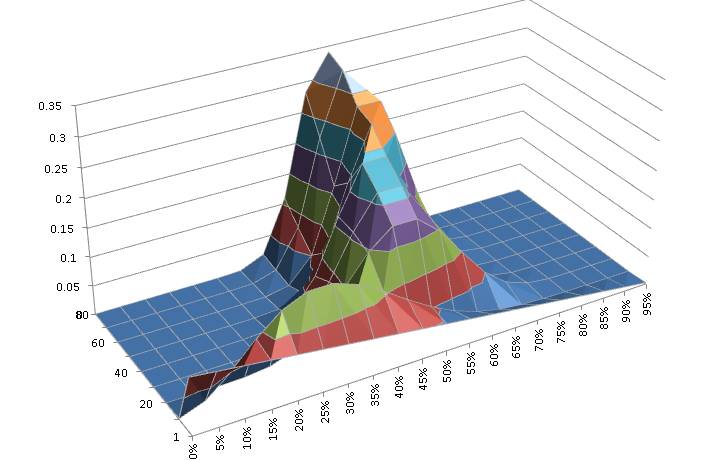

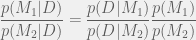
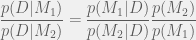
 scale on the basis of the model – the more complex the model, the lower the absolute value – but this is actually a good thing because by considering the ratio we automatically trade off complexity (when there’s little data) against descriptive value (when the simpler model doesn’t fit the data).
scale on the basis of the model – the more complex the model, the lower the absolute value – but this is actually a good thing because by considering the ratio we automatically trade off complexity (when there’s little data) against descriptive value (when the simpler model doesn’t fit the data).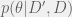 is invariant of the order in which Bayes’ rule is applied, by definition. The factorized rule cited at the end is just the result of applying the definition of data independence given the parameters.
is invariant of the order in which Bayes’ rule is applied, by definition. The factorized rule cited at the end is just the result of applying the definition of data independence given the parameters.
Recent Comments